Tell Us About a Time When You Failed
Grading my text-derived card power score against 1,231 competitive Legacy decks.
In post 2, my power score ranked Force of Will 26,269th out of 27,743 cards. Bottom 5%.
From 2022-2025, Force of Will was the single most played nonland card in the Legacy format.
Two ways to value a card
Post 2 built a static power score for every Magic card: total ability count (keywords plus semantic categories) divided by mana cost. The logic was that mana is the game’s universal currency, so abilities per mana is a reasonable first-order proxy for efficiency.
That score captures what a card says. It does not capture what it does in a real game, in a real format, against real opponents.
For that, you need a second signal. Competitive tournament results are as close to revealed preference as Magic gets. When a player registers a deck for a high-stakes event, they are making a costly claim: “these 60 cards are the best 60 cards for this format right now.” Aggregated across hundreds of events and thousands of players over four years, that signal is independent of my static scoring and derived from actual stakes.
The research question: where do the two signals agree, where do they diverge, and what does the shape of the divergence suggest?
The data
I scraped MTGTop8 for all Legacy events from 2022 through 2025: 104 events, 1,231 decks, 39,622 card-deck pairings. For each card in each deck, I tracked the quantity played, the deck’s placement, and the event’s prestige tier (a star rating MTGTop8 assigns based on event size and significance).
I then computed four prevalence metrics for every mainboard card, varying how much weight to give each deck:
| Scheme | Weight |
|---|---|
| Flat | 1 per deck |
| Placement-weighted | 8 for 1st, 7 for 2nd, …, 1 for 8th, 0 otherwise |
| Prestige-weighted | star rating of the event |
| Combined | placement × prestige |
The idea: flat weighting treats every registered deck equally. The other three ask whether the best players, at the biggest events, are playing different cards than everyone else.
Spoiler: they mostly aren’t. The top 5 cards by flat weighting (Force of Will, Brainstorm, Ponder, Daze, Swords to Plowshares) are identical across all four schemes. Legacy’s tier-one staples are so dominant that how you weight the tournament results doesn’t change who sits at the top.
The top 20 cards by combined prevalence all land between the 95th and 100th percentile under every scheme — the bars barely move. Since the choice of weighting scheme has almost no effect on which cards surface, the rest of this analysis uses flat weighting for simplicity.
The scatter
For each scored card, I computed percentile rank on both dimensions — power score (from Post 2) and flat mainboard prevalence (from tournament data) — and plotted one against the other.
The Pearson correlation between the two signals is 0.137.
For context: a correlation of 0 means the signals are entirely independent. A correlation of 1 means they are identical. At 0.137, my static text score and competitive Legacy prevalence are almost completely uncorrelated. Knowing a card’s power rank tells you nearly nothing about whether it sees Legacy play.
That sounds like a failure. It…uh…isn’t! It’s information!
Legacy is a format with a 27,000-card pool and a competitive meta that uses maybe 200-300 distinct cards. Of course most cards with high text-derived power scores don’t see Legacy play: Legacy has a power ceiling so high that “many abilities per mana” is not sufficient to compete. The format is not looking for efficiently costed creatures with lots of keywords. It is looking for the cheapest possible way to end the game or prevent the opponent from playing.
To understand why this happened, the most useful question is not “why is the correlation low” but “what is the shape of the divergence?”
What the community values that the metric doesn’t
The divergence leaderboard shows the cards where community prevalence most exceeds my text-derived metric.
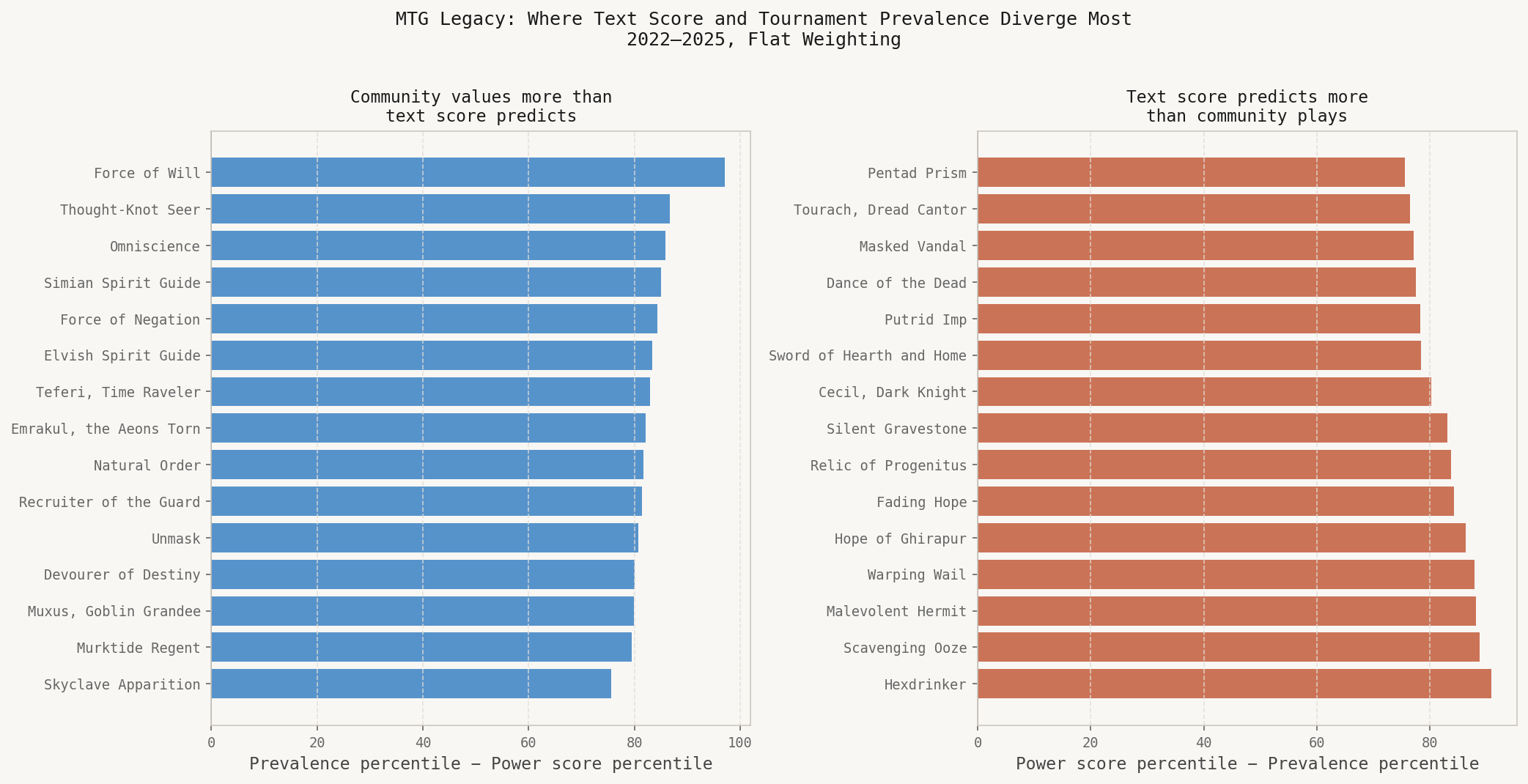
Force of Will leads by a wide margin. But look at the cards around it: Simian Spirit Guide, Force of Negation, Elvish Spirit Guide, Daze, Once Upon a Time, Unmask, Snuff Out. Every single one of these has an alternative or free casting option. You pitch a card, discard your hand, or spend zero mana to cast them.
This is not a coincidence. It is a systematic blind spot in my scoring methodology.
My metric treats mana cost as the total cost of a card. For most cards, that is approximately correct. For these cards, it is completely wrong. Force of Will costs 5 mana if you pay full retail, and zero mana if you exile a blue card from your hand. The metric scores it on the 5-mana version: a 5-CMC spell with one keyword and a conditional effect. That is a terrible card by that standard, which is why it sits at rank 26,269.
Legacy plays Force of Will in 55% of decks because the zero-mana version is the card you actually cast. The mana cost is a red herring.
The same logic applies to every card in this cluster. Simian Spirit Guide, Elvish Spirit Guide, and Once Upon a Time all have free activation modes. Daze costs zero if you bounce a land. Unmask and Snuff Out cost life instead of mana. The metric cannot see any of this because it only reads the mana cost printed in the corner.
The single most actionable finding from this analysis: alternative casting costs are a source of meaningful value, and the largest identifiable gap in my methodology. Every card with a pitch, exile-from-hand, or free-mode option is systematically underscored. My next attempt at this must identify and weight these modes.
The 330 cards I couldn’t score at all
Of the 996 mainboard cards in my tournament dataset, 330 had no power score at all. Post 2 excluded:
-
160 lands. These have no mana cost, so the efficiency ratio is undefined. Fetchlands, duals, and utility lands are the backbone of Legacy mana bases, a deck unto themselves, and cannot be scored under the current framework.
-
59 x-cost cards. When X is treated as 0 (which is what Scryfall reports for CMC), the mana cost floor is artificially low or zero. Chalice of the Void, Chrome Mox, Lotus Petal, Lion’s Eye Diamond, and Mishra’s Bauble are in this bucket. These are among Legacy’s format-definers: Lotus Petal appeared in 426 of our 1,231 decks. Chalice appeared in 145. The metric has nothing to say about any of them.
-
111 cards with no identified abilities. This is the most interesting group. These are nonland cards with CMC > 0 that the Post 2 parser could not classify into any keyword or semantic category. Looking at them, they fall into recognizable buckets:
Mana denial and land hosing. Blood Moon and Magus of the Moon (combined 80 deck appearances): “Nonbasic lands are Mountains.” Five words. No keywords. The most devastating effect in a format built on Volcanic Islands and Tropical Islands, and the metric has no way to represent it.
Prison and cost inflation. Trinisphere, Sphere of Resistance, Defense Grid, Sanctum Prelate: rules modifications that constrain what spells the opponent can cast. Short text, precise effect, enormous format impact.
Graveyard reanimation. Reanimate (157 deck appearances), Exhume, Shallow Grave: put creatures from graveyards onto the battlefield. These are the foundation of Legacy’s Reanimator strategy. Surprising that the graveyard category in Post 2 didn’t catch them.
Unique combo enablers. Thassa’s Oracle, Doomsday, Show and Tell, Sneak Attack, Ad Nauseam: each enables a specific win condition in a way that has no keyword and no template. The oracle text is novel enough that the parser had nothing to match against.
The through-line across most of these: they are rule modification effects, expressed in as few words as possible. “Nonbasic lands are Mountains” is a more powerful statement than a paragraph of triggered abilities, but a keyword-density metric cannot see that. A future version of the scoring system needs a way to represent constraint and lock effects, not just card-advantage and combat-oriented text.
What the metric scores that the community doesn’t
The other direction is quieter but worth naming.
The cards where the metric scores far above Legacy prevalence are almost uniformly Modern powerhouses: Hexdrinker, Scavenging Ooze, Malevolent Hermit. High keyword counts, efficient mana costs, strong effects by most formats’ standards.
Legacy simply does not want them. The format’s power level is high enough that “fair but efficient” doesn’t compete. A 1-mana creature with two keywords is a respectable Modern card and an irrelevant Legacy card if it doesn’t do something the format specifically needs in the first two turns. The metric correctly identifies these as efficient cards; the community correctly identifies them as not good enough for this particular format.
This is probably the cleanest finding in the negative gap: the metric measures efficiency relative to all ~27,000 cards, but Legacy enforces a much higher local ceiling. A card can be in the top 5% of the full card pool and still be unplayable in Legacy. The format has its own power curve, and the metric is blind to it.
What it all means
The text-derived metric is format-agnostic. It scores every card against every other card, across all CMC tiers and all formats. It captures how much a card does per mana by the letter of its text. That is useful for tracking power creep over time, comparing cards within a CMC tier, or identifying efficiency outliers across the full catalog.
Competitive Legacy prevalence is format-specific revealed preference. It tells you what the best players decided was worth playing, in one specific format, under real stakes. It is not a claim about what is objectively good, but it is pretty close.
Where the two signals diverge, there are two possible explanations for any given card: the metric is missing something real (alternative costs, rule modifications, format context), or the community has a blind spot. The obvious non-randomness of the divergence tells me that the issue is the former.
What’s next
The alternative-cost gap is my metric’s most obvious weakness, and it’s specific enough to act on! The next version of the metric needs to:
- Identify pitch costs, exile-from-hand modes, and life-payment alternatives in oracle text
- Compute a “minimum effective cost” rather than using CMC directly
- Handle X costs as a variable rather than defaulting to 0
The rule modification gap (Blood Moon, Trinisphere, etc.) is harder: these effects are expressed in plain English with no keyword, and building a parser that recognizes “this sentence constrains opponent agency” is genuinely difficult. That one goes in the backlog.
The x-cost exclusion is, in retrospect, a known limitation that became visible only when we could compare against format data. Lotus Petal in 35% of Legacy decks is a strong signal that ”0: Add one mana of any color” is doing something the efficiency ratio never captured.
Data: 104 Legacy events from MTGTop8, 2022–2025. 1,231 decks, 39,622 card appearances. Power scores from Post 2. Analysis code available in the GitHub repo.